4.8 - UNet Image segmentation
Contents
4.8 - UNet Image segmentation¶
!wget -nc --no-cache -O init.py -q https://raw.githubusercontent.com/rramosp/2021.deeplearning/main/content/init.py
import init; init.init(force_download=False);
replicating local resources
Some general references on segmentation¶
Use GPU runtime!!!¶
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
%load_ext tensorboard
from sklearn.datasets import *
from local.lib import mlutils
tf.__version__
'2.4.1'
# this will only work if you have a GPU environment
!nvidia-smi
Sat Mar 20 21:06:07 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.56 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 37C P8 10W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Image Segmentation¶
This notebook is adapted from this Keras Competition: Data Science Bowl 2018
https://www.kaggle.com/keegil/keras-u-net-starter-lb-0-277/notebook
From the competition Data Section download the file stage1_train.zip and stage1_test.zip, unzip them, make it available somewhere in the file system and update the TRAIN_PATH and TEST_PATH variables accordingly below.
Alternatively, you can use the kaggle api to download them automatically. This is convenient in Google Colab since the data transfer will happen directly between kaggle and colab. To do this
download the
kaggle.jsonfile from your Kaggle account under Create new API tokenupload it to your Colab notebook environment
execute the following cell
If kaggle utilities are not installed in your environment make sure to also execute
pip install kaggle
%%bash
export KAGGLE_CONFIG_DIR=.
kaggle competitions download data-science-bowl-2018 -f stage1_train.zip
kaggle competitions download data-science-bowl-2018 -f stage1_test.zip
Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 ./kaggle.json'
Downloading stage1_train.zip to /content
Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 ./kaggle.json'
Downloading stage1_test.zip to /content
0%| | 0.00/79.1M [00:00<?, ?B/s]
6%|6 | 5.00M/79.1M [00:00<00:02, 36.0MB/s]
20%|## | 16.0M/79.1M [00:00<00:01, 45.2MB/s]
37%|###6 | 29.0M/79.1M [00:00<00:00, 56.4MB/s]
72%|#######2 | 57.0M/79.1M [00:00<00:00, 74.3MB/s]
89%|########8 | 70.0M/79.1M [00:00<00:00, 81.5MB/s]
100%|##########| 79.1M/79.1M [00:00<00:00, 125MB/s]
0%| | 0.00/9.10M [00:00<?, ?B/s]
55%|#####4 | 5.00M/9.10M [00:00<00:00, 32.0MB/s]
100%|##########| 9.10M/9.10M [00:00<00:00, 44.6MB/s]
!unzip -o stage1_test.zip -d stage1_test > /dev/null
!unzip -o stage1_train.zip -d stage1_train > /dev/null
Intro¶
Hello! This rather quick and dirty kernel shows how to get started on segmenting nuclei using a neural network in Keras.
The architecture used is the so-called U-Net, which is very common for image segmentation problems such as this. I believe they also have a tendency to work quite well even on small datasets.
Let’s get started importing everything we need!
from progressbar import progressbar as pbar
import os
import sys
import random
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from itertools import chain
from skimage.io import imread, imshow, imread_collection, concatenate_images
from skimage.transform import resize
from skimage.morphology import label
from tensorflow.keras.models import Model, load_model
from tensorflow.keras.layers import Input, Flatten
from tensorflow.keras.layers import Dropout, Lambda
from tensorflow.keras.layers import Conv2D, Conv2DTranspose
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import concatenate
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras import backend as K
import tensorflow as tf
print (tf.__version__)
# Set some parameters
IMG_WIDTH = 128
IMG_HEIGHT = 128
IMG_CHANNELS = 3
TRAIN_PATH = 'stage1_train/'
TEST_PATH = 'stage1_test/'
warnings.filterwarnings('ignore', category=UserWarning, module='skimage')
seed = 42
random.seed = seed
np.random.seed = seed
2.4.1
# Get train and test IDs
train_ids = next(os.walk(TRAIN_PATH))[1]
test_ids = next(os.walk(TEST_PATH))[1]
Get the data¶
Let’s first import all the images and associated masks. I downsample both the training and test images to keep things light and manageable, but we need to keep a record of the original sizes of the test images to upsample our predicted masks and create correct run-length encodings later on. There are definitely better ways to handle this, but it works fine for now!
Observe some image sizes and their variability
for n, id_ in enumerate(np.random.permutation(train_ids)[:10]):
path = TRAIN_PATH + id_
img = imread(path + '/images/' + id_ + '.png')[:,:,:IMG_CHANNELS]
print(img.shape)
(360, 360, 3)
(256, 256, 3)
(256, 256, 3)
(256, 256, 3)
(256, 256, 3)
(256, 256, 3)
(256, 256, 3)
(256, 256, 3)
(256, 256, 3)
(256, 256, 3)
# Get and resize train images and masks
X_train = np.zeros((len(train_ids), IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS), dtype=np.uint8)
Y_train = np.zeros((len(train_ids), IMG_HEIGHT, IMG_WIDTH, 1), dtype=np.bool)
print('Getting and resizing train images and masks ... ')
sys.stdout.flush()
for n, id_ in pbar(enumerate(train_ids), max_value=len(train_ids)):
path = TRAIN_PATH + id_
img = imread(path + '/images/' + id_ + '.png')[:,:,:IMG_CHANNELS]
img = resize(img, (IMG_HEIGHT, IMG_WIDTH), mode='constant', preserve_range=True)
X_train[n] = img
mask = np.zeros((IMG_HEIGHT, IMG_WIDTH, 1), dtype=np.bool)
for mask_file in next(os.walk(path + '/masks/'))[2]:
mask_ = imread(path + '/masks/' + mask_file)
mask_ = np.expand_dims(resize(mask_, (IMG_HEIGHT, IMG_WIDTH), mode='constant',
preserve_range=True), axis=-1)
mask = np.maximum(mask, mask_)
Y_train[n] = mask
# Get and resize test images
X_test = np.zeros((len(test_ids), IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS), dtype=np.uint8)
sizes_test = []
print('Getting and resizing test images ... ')
sys.stdout.flush()
for n, id_ in pbar(enumerate(test_ids), max_value=len(test_ids)):
path = TEST_PATH + id_
img = imread(path + '/images/' + id_ + '.png')[:,:,:IMG_CHANNELS]
sizes_test.append([img.shape[0], img.shape[1]])
img = resize(img, (IMG_HEIGHT, IMG_WIDTH), mode='constant', preserve_range=True)
X_test[n] = img
print('Done!')
Getting and resizing train images and masks ...
100% (670 of 670) |######################| Elapsed Time: 0:05:51 Time: 0:05:51
Getting and resizing test images ...
100% (65 of 65) |########################| Elapsed Time: 0:00:01 Time: 0:00:01
Done!
# selected VALIDATION IDs
ids = [61, 59, 24, 39, 49]
Let’s see if things look all right by drawing some random images and their associated masks.
def show_img(img, title="", cmap=None, details=True):
plt.imshow(img, cmap=cmap)
if details:
plt.title("%s min %d, max %d\nshape %s"%(title, np.min(img), np.max(img), str(img.shape)))
else:
plt.title(title)
plt.axis("off")
ival = int(X_train.shape[0]*0.9)
print(ival)
plt.figure(figsize=(15,6))
print (ids)
for c,i in enumerate(ids):
plt.subplot(2,5,c+1)
img = X_train[ival+i]
show_img(img, "IMAGE %d"%i)
plt.subplot(2,5,c+6)
show_img(np.squeeze(Y_train[ival+i]), "LABEL %d"%i, cmap=plt.cm.Greys_r)
603
[61, 59, 24, 39, 49]
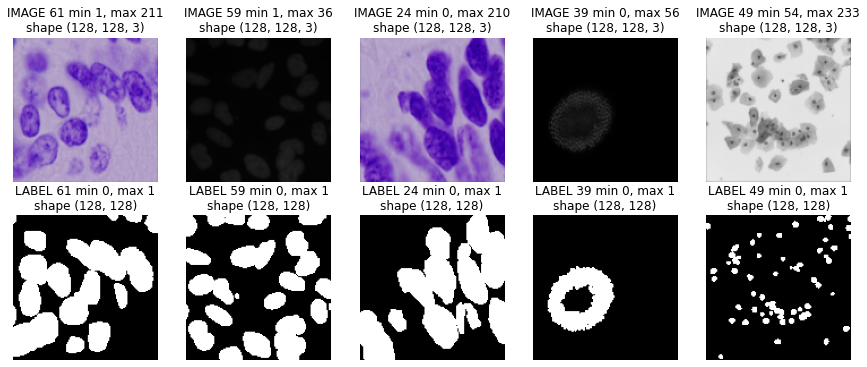
Seems good!
Build and train our neural network¶
Next we build our U-Net model, loosely based on U-Net: Convolutional Networks for Biomedical Image Segmentation and very similar to this repo from the Kaggle Ultrasound Nerve Segmentation competition.

def get_model_UNET(IMG_HEIGHT=128, IMG_WIDTH=128, IMG_CHANNELS=3):
# Build U-Net model
inputs = Input((IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS))
s = Lambda(lambda x: x / 255) (inputs)
c1 = Conv2D(16, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (s)
c1 = Dropout(0.1) (c1)
c1 = Conv2D(16, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c1)
p1 = MaxPooling2D((2, 2)) (c1)
c2 = Conv2D(32, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (p1)
c2 = Dropout(0.1) (c2)
c2 = Conv2D(32, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c2)
p2 = MaxPooling2D((2, 2)) (c2)
c3 = Conv2D(64, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (p2)
c3 = Dropout(0.2) (c3)
c3 = Conv2D(64, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c3)
p3 = MaxPooling2D((2, 2)) (c3)
c4 = Conv2D(128, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (p3)
c4 = Dropout(0.2) (c4)
c4 = Conv2D(128, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c4)
p4 = MaxPooling2D(pool_size=(2, 2)) (c4)
c5 = Conv2D(256, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (p4)
c5 = Dropout(0.3) (c5)
c5 = Conv2D(256, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c5)
u6 = Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same') (c5)
u6 = concatenate([u6, c4])
c6 = Conv2D(128, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (u6)
c6 = Dropout(0.2) (c6)
c6 = Conv2D(128, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c6)
u7 = Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same') (c6)
u7 = concatenate([u7, c3])
c7 = Conv2D(64, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (u7)
c7 = Dropout(0.2) (c7)
c7 = Conv2D(64, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c7)
u8 = Conv2DTranspose(32, (2, 2), strides=(2, 2), padding='same') (c7)
u8 = concatenate([u8, c2])
c8 = Conv2D(32, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (u8)
c8 = Dropout(0.1) (c8)
c8 = Conv2D(32, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c8)
u9 = Conv2DTranspose(16, (2, 2), strides=(2, 2), padding='same') (c8)
u9 = concatenate([u9, c1], axis=3)
c9 = Conv2D(16, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (u9)
c9 = Dropout(0.1) (c9)
c9 = Conv2D(16, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c9)
outputs = Conv2D(1, (1, 1), activation='sigmoid') (c9)
model = Model(inputs=[inputs], outputs=[outputs])
model.compile(optimizer='adam', loss='binary_crossentropy')
return model
model = get_model_UNET()
model.summary()
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 128, 128, 3) 0
__________________________________________________________________________________________________
lambda (Lambda) (None, 128, 128, 3) 0 input_1[0][0]
__________________________________________________________________________________________________
conv2d (Conv2D) (None, 128, 128, 16) 448 lambda[0][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 128, 128, 16) 0 conv2d[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 128, 128, 16) 2320 dropout[0][0]
__________________________________________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 64, 64, 16) 0 conv2d_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 64, 64, 32) 4640 max_pooling2d[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 64, 64, 32) 0 conv2d_2[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 64, 64, 32) 9248 dropout_1[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 32, 32, 32) 0 conv2d_3[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 32, 32, 64) 18496 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
dropout_2 (Dropout) (None, 32, 32, 64) 0 conv2d_4[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, 32, 32, 64) 36928 dropout_2[0][0]
__________________________________________________________________________________________________
max_pooling2d_2 (MaxPooling2D) (None, 16, 16, 64) 0 conv2d_5[0][0]
__________________________________________________________________________________________________
conv2d_6 (Conv2D) (None, 16, 16, 128) 73856 max_pooling2d_2[0][0]
__________________________________________________________________________________________________
dropout_3 (Dropout) (None, 16, 16, 128) 0 conv2d_6[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 16, 16, 128) 147584 dropout_3[0][0]
__________________________________________________________________________________________________
max_pooling2d_3 (MaxPooling2D) (None, 8, 8, 128) 0 conv2d_7[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 8, 8, 256) 295168 max_pooling2d_3[0][0]
__________________________________________________________________________________________________
dropout_4 (Dropout) (None, 8, 8, 256) 0 conv2d_8[0][0]
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, 8, 8, 256) 590080 dropout_4[0][0]
__________________________________________________________________________________________________
conv2d_transpose (Conv2DTranspo (None, 16, 16, 128) 131200 conv2d_9[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 16, 16, 256) 0 conv2d_transpose[0][0]
conv2d_7[0][0]
__________________________________________________________________________________________________
conv2d_10 (Conv2D) (None, 16, 16, 128) 295040 concatenate[0][0]
__________________________________________________________________________________________________
dropout_5 (Dropout) (None, 16, 16, 128) 0 conv2d_10[0][0]
__________________________________________________________________________________________________
conv2d_11 (Conv2D) (None, 16, 16, 128) 147584 dropout_5[0][0]
__________________________________________________________________________________________________
conv2d_transpose_1 (Conv2DTrans (None, 32, 32, 64) 32832 conv2d_11[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 32, 32, 128) 0 conv2d_transpose_1[0][0]
conv2d_5[0][0]
__________________________________________________________________________________________________
conv2d_12 (Conv2D) (None, 32, 32, 64) 73792 concatenate_1[0][0]
__________________________________________________________________________________________________
dropout_6 (Dropout) (None, 32, 32, 64) 0 conv2d_12[0][0]
__________________________________________________________________________________________________
conv2d_13 (Conv2D) (None, 32, 32, 64) 36928 dropout_6[0][0]
__________________________________________________________________________________________________
conv2d_transpose_2 (Conv2DTrans (None, 64, 64, 32) 8224 conv2d_13[0][0]
__________________________________________________________________________________________________
concatenate_2 (Concatenate) (None, 64, 64, 64) 0 conv2d_transpose_2[0][0]
conv2d_3[0][0]
__________________________________________________________________________________________________
conv2d_14 (Conv2D) (None, 64, 64, 32) 18464 concatenate_2[0][0]
__________________________________________________________________________________________________
dropout_7 (Dropout) (None, 64, 64, 32) 0 conv2d_14[0][0]
__________________________________________________________________________________________________
conv2d_15 (Conv2D) (None, 64, 64, 32) 9248 dropout_7[0][0]
__________________________________________________________________________________________________
conv2d_transpose_3 (Conv2DTrans (None, 128, 128, 16) 2064 conv2d_15[0][0]
__________________________________________________________________________________________________
concatenate_3 (Concatenate) (None, 128, 128, 32) 0 conv2d_transpose_3[0][0]
conv2d_1[0][0]
__________________________________________________________________________________________________
conv2d_16 (Conv2D) (None, 128, 128, 16) 4624 concatenate_3[0][0]
__________________________________________________________________________________________________
dropout_8 (Dropout) (None, 128, 128, 16) 0 conv2d_16[0][0]
__________________________________________________________________________________________________
conv2d_17 (Conv2D) (None, 128, 128, 16) 2320 dropout_8[0][0]
__________________________________________________________________________________________________
conv2d_18 (Conv2D) (None, 128, 128, 1) 17 conv2d_17[0][0]
==================================================================================================
Total params: 1,941,105
Trainable params: 1,941,105
Non-trainable params: 0
__________________________________________________________________________________________________
Update: Changed to ELU units, added dropout.
Next we fit the model on the training data, using a validation split of 0.1. We use a small batch size because we have so little data. I recommend using checkpointing and early stopping when training your model. I won’t do it here to make things a bit more reproducible (although it’s very likely that your results will be different anyway). I’ll just train for 10 epochs, which takes around 10 minutes in the Kaggle kernel with the current parameters.
Update: Added early stopping and checkpointing and increased to 30 epochs.
you may skip this step by downloading directly the pretrained weights¶
!wget -nc https://s3.amazonaws.com/rlx/model-dsbowl2018-1.h5
File ‘model-dsbowl2018-1.h5’ already there; not retrieving.
# Fit model
earlystopper = EarlyStopping(patience=5, verbose=1)
checkpointer = ModelCheckpoint('model-dsbowl2018-1.h5', verbose=1, save_best_only=True)
results = model.fit(X_train, Y_train, validation_split=0.1, batch_size=8, epochs=30,
callbacks=[earlystopper, checkpointer])
Epoch 1/30
76/76 [==============================] - 37s 35ms/step - loss: 0.4688 - val_loss: 0.2949
Epoch 00001: val_loss improved from inf to 0.29486, saving model to model-dsbowl2018-1.h5
Epoch 2/30
76/76 [==============================] - 2s 22ms/step - loss: 0.1743 - val_loss: 0.1939
Epoch 00002: val_loss improved from 0.29486 to 0.19387, saving model to model-dsbowl2018-1.h5
Epoch 3/30
76/76 [==============================] - 2s 22ms/step - loss: 0.1445 - val_loss: 0.1649
Epoch 00003: val_loss improved from 0.19387 to 0.16486, saving model to model-dsbowl2018-1.h5
Epoch 4/30
76/76 [==============================] - 2s 22ms/step - loss: 0.1457 - val_loss: 0.1190
Epoch 00004: val_loss improved from 0.16486 to 0.11898, saving model to model-dsbowl2018-1.h5
Epoch 5/30
76/76 [==============================] - 2s 22ms/step - loss: 0.1252 - val_loss: 0.1301
Epoch 00005: val_loss did not improve from 0.11898
Epoch 6/30
76/76 [==============================] - 2s 22ms/step - loss: 0.1107 - val_loss: 0.1116
Epoch 00006: val_loss improved from 0.11898 to 0.11157, saving model to model-dsbowl2018-1.h5
Epoch 7/30
76/76 [==============================] - 2s 22ms/step - loss: 0.1038 - val_loss: 0.0940
Epoch 00007: val_loss improved from 0.11157 to 0.09399, saving model to model-dsbowl2018-1.h5
Epoch 8/30
76/76 [==============================] - 2s 22ms/step - loss: 0.1017 - val_loss: 0.0907
Epoch 00008: val_loss improved from 0.09399 to 0.09072, saving model to model-dsbowl2018-1.h5
Epoch 9/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0972 - val_loss: 0.0890
Epoch 00009: val_loss improved from 0.09072 to 0.08904, saving model to model-dsbowl2018-1.h5
Epoch 10/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0887 - val_loss: 0.0864
Epoch 00010: val_loss improved from 0.08904 to 0.08641, saving model to model-dsbowl2018-1.h5
Epoch 11/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0922 - val_loss: 0.1307
Epoch 00011: val_loss did not improve from 0.08641
Epoch 12/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0960 - val_loss: 0.0943
Epoch 00012: val_loss did not improve from 0.08641
Epoch 13/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0907 - val_loss: 0.0836
Epoch 00013: val_loss improved from 0.08641 to 0.08361, saving model to model-dsbowl2018-1.h5
Epoch 14/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0860 - val_loss: 0.0847
Epoch 00014: val_loss did not improve from 0.08361
Epoch 15/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0773 - val_loss: 0.0878
Epoch 00015: val_loss did not improve from 0.08361
Epoch 16/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0831 - val_loss: 0.0849
Epoch 00016: val_loss did not improve from 0.08361
Epoch 17/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0849 - val_loss: 0.0780
Epoch 00017: val_loss improved from 0.08361 to 0.07798, saving model to model-dsbowl2018-1.h5
Epoch 18/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0921 - val_loss: 0.0812
Epoch 00018: val_loss did not improve from 0.07798
Epoch 19/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0787 - val_loss: 0.0767
Epoch 00019: val_loss improved from 0.07798 to 0.07668, saving model to model-dsbowl2018-1.h5
Epoch 20/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0749 - val_loss: 0.0791
Epoch 00020: val_loss did not improve from 0.07668
Epoch 21/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0781 - val_loss: 0.0787
Epoch 00021: val_loss did not improve from 0.07668
Epoch 22/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0796 - val_loss: 0.0769
Epoch 00022: val_loss did not improve from 0.07668
Epoch 23/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0728 - val_loss: 0.0753
Epoch 00023: val_loss improved from 0.07668 to 0.07530, saving model to model-dsbowl2018-1.h5
Epoch 24/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0748 - val_loss: 0.0782
Epoch 00024: val_loss did not improve from 0.07530
Epoch 25/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0794 - val_loss: 0.0715
Epoch 00025: val_loss improved from 0.07530 to 0.07148, saving model to model-dsbowl2018-1.h5
Epoch 26/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0703 - val_loss: 0.0731
Epoch 00026: val_loss did not improve from 0.07148
Epoch 27/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0731 - val_loss: 0.0743
Epoch 00027: val_loss did not improve from 0.07148
Epoch 28/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0715 - val_loss: 0.0754
Epoch 00028: val_loss did not improve from 0.07148
Epoch 29/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0716 - val_loss: 0.0741
Epoch 00029: val_loss did not improve from 0.07148
Epoch 30/30
76/76 [==============================] - 2s 22ms/step - loss: 0.0691 - val_loss: 0.0739
Epoch 00030: val_loss did not improve from 0.07148
Epoch 00030: early stopping
All right, looks good! Loss seems to be a bit erratic, though. I’ll leave it to you to improve the model architecture and parameters!
Make predictions¶
Let’s make predictions both on the test set, the val set and the train set (as a sanity check). Remember to load the best saved model if you’ve used early stopping and checkpointing.
# Predict on train, val and test
model = load_model('model-dsbowl2018-1.h5')
preds_train = model.predict(X_train[:ival], verbose=1)
preds_val = model.predict(X_train[ival:], verbose=1)
preds_test = model.predict(X_test, verbose=1)
# Threshold predictions
preds_train_t = (preds_train > 0.5).astype(np.uint8)
preds_val_t = (preds_val > 0.5).astype(np.uint8)
preds_test_t = (preds_test > 0.5).astype(np.uint8)
# Create list of upsampled test masks
preds_test_upsampled = []
for i in range(len(preds_test)):
preds_test_upsampled.append(resize(np.squeeze(preds_test[i]),
(sizes_test[i][0], sizes_test[i][1]),
mode='constant', preserve_range=True))
19/19 [==============================] - 2s 50ms/step
3/3 [==============================] - 0s 19ms/step
3/3 [==============================] - 0s 147ms/step
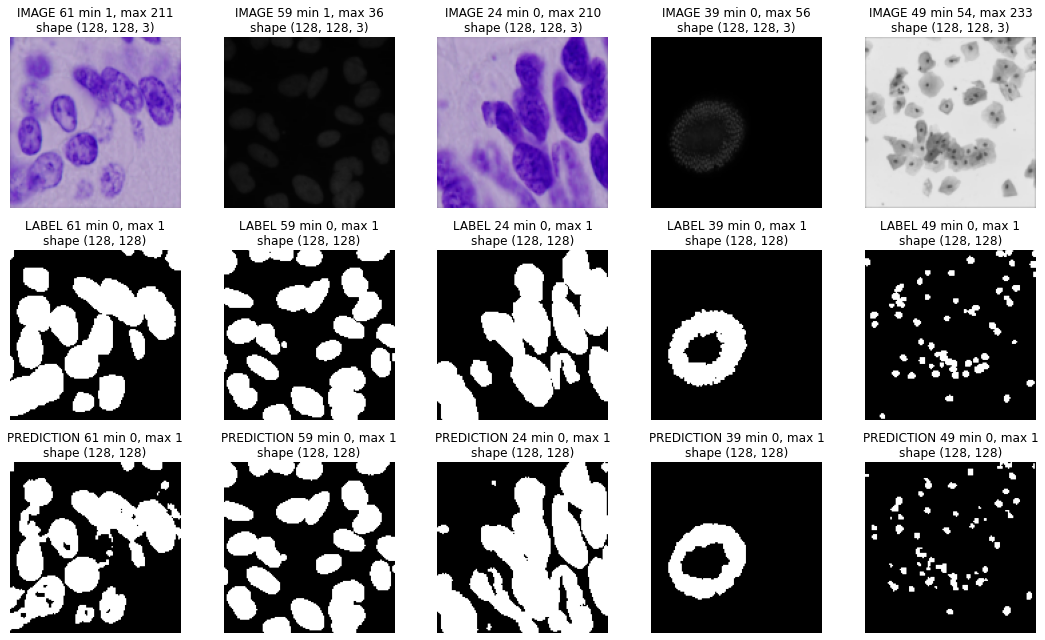
performance on selected validation data¶
plt.figure(figsize=(15,9))
for c,i in enumerate(ids):
plt.subplot(3,5,c+1)
show_img(X_train[ival+i], "IMAGE %d"%i)
plt.subplot(3,5,c+6)
show_img(np.squeeze(Y_train[ival+i]), "LABEL %d"%i, cmap=plt.cm.Greys_r)
plt.subplot(3,5,c+11)
show_img(np.squeeze(preds_val_t[i]), "PREDICTION %d"%i, cmap=plt.cm.Greys_r)
plt.tight_layout()
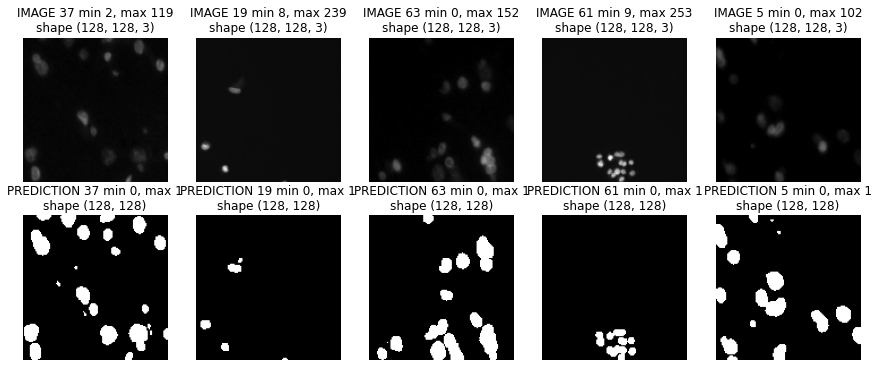
And on test data¶
The model is at least able to fit to the training data! Certainly a lot of room for improvement even here, but a decent start. How about the validation data?
plt.figure(figsize=(15,6))
ids = np.random.permutation(len(preds_test))[:5]
for c,i in enumerate(ids):
plt.subplot(2,5,c+1)
show_img(X_test[i], "IMAGE %d"%i)
plt.subplot(2,5,c+6)
show_img(np.squeeze(preds_test_t[i]), "PREDICTION %d"%i, cmap=plt.cm.Greys_r)